¿Está escrito? Pasalo a audio: Google AI Studio y un podcast sintético superador
![]()
El martes 1 de julio llegó a las casillas de correo de más de 1500 suscriptores el número #3 de AMI clicks, el newsletter del programa de Educación sobre Alfabetización Mediática e Informacional. Una vez más, nos encontramos ante el desafío de pasar el texto a audio y, aunque quedamos conformes con las versiones sonoras de las ediciones anteriores, también encontramos distintos desafíos al usar Notebook LM que nos llevaron a seguir buscando nuevas herramientas (si no leíste el artículo anterior, podés hacerlo acá y conocer los primeros pasos de esta creación experimental).
Entonces, en esta ocasión, probamos la herramienta Google AI Studio. En comparación con Notebook LM ofrece mayor complejidad, pero también tiene más alternativas de uso y de personalización del contenido.
Aquí vamos a guiarlos paso a paso para que puedan crear su propio podcast como lo hicimos nosotros, sin abrumarse en el camino y aprovechando al máximo las opciones para hacerlo propio.
Sobre Google AI Studio
Esta herramienta, disponible para todas las cuentas de Google de manera gratuita, está pensada para desarrolladores, investigadores y público general con interés en indagar en las funcionalidades de IA Generativa. La plataforma permite trabajar con diferentes modelos dentro de una misma interfaz, escribir código e interactuar tanto a través de texto como por comando de voz.
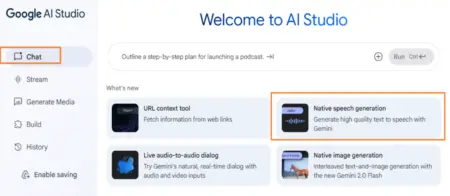
Así se ve la interfaz. En este caso vamos a centrarnos en la funcionalidad “Native speech generation” para generar audio en alta definición partiendo de texto. Es importante, antes de avanzar, que tengan presente que estamos trabajando dentro de la pestaña “Chat” del menú. Hay otras funcionalidades interesantes, pero que no hacen a nuestro objetivo. Por supuesto pueden explorarlas.
Otra aclaración útil: el sitio web está en inglés, pero pueden traducirlo utilizando la aplicación del navegador.

¿Por dónde empezar?
El primer paso es seleccionar el texto que quieran convertir en audio. En nuestro caso es el número #3 de AMI Clicks sobre cuidados digitales (pueden leerlo aquí).
Lo siguiente será preguntarse por el formato deseado. Si la búsqueda es un podcast deberemos seleccionar “Multispeaker audio”, lo que habilitará dos narradores que alternan la palabra simulando un diálogo.
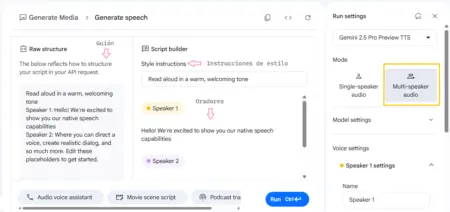
Hay que comenzar por la columna de la derecha, “Run settings” o “Configuración de ejecución”, donde tenemos 3 decisiones que tomar:
1. ¿Qué modelo queremos utilizar? En nuestro caso usamos el que viene por defecto, Gemini 2.5 Pro Preview TTS.
2. Al desplegar “Model settings” o “Configuración del modelo” nos encontramos con una barra que permite regular la temperatura. En los LLM o Grandes Modelos de Lenguaje, la temperatura refiere a cuán “creativo” le permitimos ser al modelo al generar respuestas. Una temperatura más baja generará frases más probables o predecibles, mientras que una temperatura más alta permitirá mayor aleatoriedad. Ante la frase “el día está…” el modelo puede completar “soleado” o puede completar “impredecible”, ambas opciones son correctas gramaticalmente, pero una es más frecuente que la otra.
3. Nombre y voces de quienes narran: el nombre por default es Speaker 1 y 2, es decir Narrador 1 y 2. No es necesario que seleccionemos un nombre, pero sí es importante que el nombre que aparezca en esta columna coincida con el que usemos en el guión. Si en el guión los llamamos Presentadora 1 y Presentador 2 debemos mantener ese nombre en esta columna. En cuanto a las voces, hay algunas descripciones de qué sensación genera cada una. Nuestra recomendación es que exploren cuál consideran que hace más sentido con el tono y el clima que quieren generar. Nuestra selección fue Despina y Puck.
Generar el guión
Habiendo seleccionado la configuración deseada, es momento de enfocarnos en el contenido de nuestro podcast. Para eso, deberemos crear un guión que delimite la conversación entre los narradores. Esta fue la parte más desafiante, ya que en nuestro newsletter aparecen muchos recursos y enlaces además del texto que lo estructura. Por lo tanto, tuvimos que pensar qué queríamos resaltar y qué partes del contenido dejar exclusivamente en la versión escrita.
Para eso, utilizamos a ChatGPT como asistente: le brindamos la selección del contenido, qué importancia queríamos darle y la duración estimada de la conversación.
Es importante aclarar que esto sirve solamente para una primera versión, será necesario darle un tono propio y engrosar algunos segmentos. Si sirve de referencia, buscábamos un audio de aproximadamente 10 minutos y el texto generado por GPT (con ese requisito y sin nuestra intervención) fue de la mitad.
Cuando queden conformes con el guión, es momento de pasarlo al cuadro “Raw structure” o “Estructura cruda”. Recuerden verificar que el nombre de los narradores sea el mismo que el del recuadro anterior y eliminar signos y emojis que puedan haber quedado del texto base. Algo que nos resultó útil para organizar el diálogo fue delimitar bloques de contenido y dejarlos explicitados en el guión.
¡Al aire!
Ahora sí, momento de probar cómo se escucha nuestro podcast. En función de lo que aprendimos les compartimos algunas sugerencias:
– Recomendamos testear las voces de los anfitriones con un texto de prueba que sea breve y no en la versión completa ya que tarda unos minutos en generarse (y tarda más cuanto más contenido sea).
– Aprovechar estas pruebas breves para evaluar si el tono y el acento condicen con lo que esperaban. Recuerden que en la columna de “Style instructions” pueden dejar pedidos de cómo deberían pronunciar las frases: volumen, énfasis, efecto.
– Como toda generación con IAG, pueden haber alucinaciones y que haya palabras mal pronunciadas, fragmentos de texto que se “cuelen” en otro idioma, nombres o siglas que suenen extraño o glitches entre frases. Por eso es importante apostar a “prueba y error”. Luego de escuchar la primera versión podrán hacer los ajustes que necesiten. Tengan en cuenta que algunos errores pueden resolverse simplemente generando el audio de nuevo.
En nuestra experiencia, esta herramienta implica más trabajo de preproducción, pero la posibilidad de guionar palabra a palabra lo que dirá el audio abre un mundo de posibilidades. Los narradores que probamos suenan orgánicos y, aunque no reemplaza las potencia de un podcast grabado y editado por personas, sí propone un universo interesante para habilitar el contenido para quienes no pueden leerlo por cuestiones de accesibilidad o porque quieren consumirlo mientras hacen otra cosa (manejar, cocinar, etc.).
Para explorar las posibilidades del programa, hicimos una prueba cortita: buscamos generar un tono de historia de terror y que respete el acento rioplatense. Llevó algunos intentos pero quedó muy bien, les dejamos la captura para que lo vean en acción y el resultado en audio.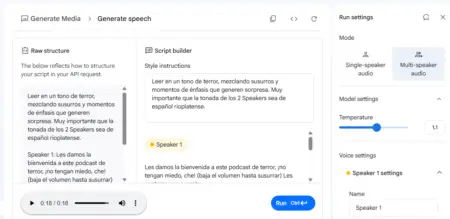
👉 Audio de prueba: “terror” con acento rioplatense.
Entusiasma ver que las limitaciones que encontramos al utilizar NotebookLM aparecen saldadas con Google AI Studio. Aquí encontrarán la versión en audio que enviamos con el newsletter: nuevamente, fue el enlace más clickeado 🥳.
👉 Versión en audio de AMI clicks #3
¿Utilizaron otras herramientas para crear podcasts sintéticos? Pueden contarnos en comentarios y las probamos. Mientras, nos preparamos para una próxima edición donde el podcast sintético incorpore… música. 🎵
¿Les intriga? Podemos contarles en la siguiente entrega.
Comentarios
Valoramos mucho la opinión de nuestra comunidad de lectores y siempre estamos a favor del debate y del intercambio. Por eso es importante para nosotros generar un espacio de respeto y cuidado, por lo que por favor tené en cuenta que no publicaremos comentarios con insultos, agresiones o mensajes de odio, desinformaciones que pudieran resultar peligrosas para otros, información personal, o promoción o venta de productos.
Muchas gracias